Tracking supermarket prices with playwright
Aug 6, 2024 • 2126 words • 11 min read
Back in Dec 2022, when inflation was running high, I built a website for tracking price changes in the three largest supermarkets of my home country, Greece.
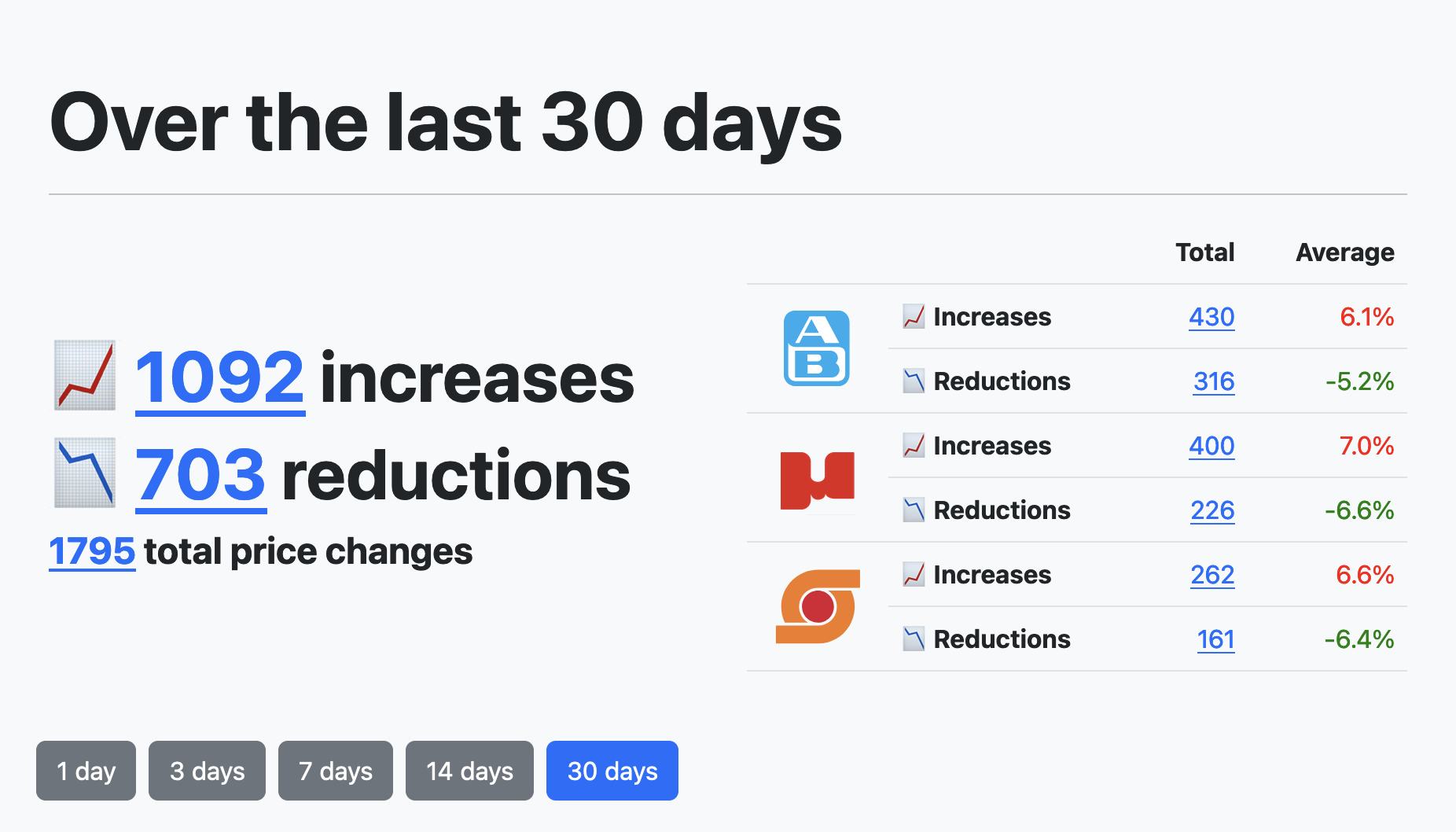
In the process I ran into a few interesting hurdles that I had to clear before being able to "go live". There were also several lessons I learned and faulty assumptions that I made.
In this post I will talk about scraping: What I use, where it runs, how I got around some restrictions and how I got it to the point that it can run for months without intervention.
Table of contents
- Scraping js sites
- Automating
- Avoiding IP restrictions
- How and when does it fail?
- Optimising
- Cost
- Conclusion
Scraping js sites
The main problem was, what else? Javascript.
All three eshops are rendered with js and even in the few spots where they don't, they
still rely on js to load products as you scroll, similar to infinite scrolling in social
media. This means that using plain simple curl or requests.get() was out of the
question; I needed something that could run js.
Enter Playwright.
Playwright allows you to programmatically control a web browser, providing an API to handle almost everything, from opening a new tab and navigating to a URL, to inspecting the DOM, retrieving element details, and intercepting and inspecting requests.
It also supports Chromium, Safari and Firefox browsers and you can use it with Node, Java, .NET and, most importantly, Python.
With this in my belt, doing the scrolling and the loading of the products looked like this:
def visit_links(self):
#
# <truncated>
#
# do the infinite scrolling
load_more_locator = self.page.get_by_test_id(
"vertical-load-more-wrapper"
).all()
while len(load_more_locator) == 1:
load_more_locator[0].scroll_into_view_if_needed()
load_more_locator = self.page.get_by_test_id(
"vertical-load-more-wrapper"
).all()
# once the infinite scroll is finished, load all the products
products = self.page.locator("li.product-item").all()
# and then ensure that we only keep products that don't have the "unavailable" text
products = [
p
for p in products
if len(p.get_by_test_id("product-block-unavailable-text").all()) == 0
]
#
# <truncated>
#
By the end of this method, I have a list of product <div>s, each containing the
product's name, price, photo, link, etc, that I get to parse to extract this information.
Then I do the same for the next product category, and so on.
Once I wrote the scrapers for all 3 supermarkets, the next step was to run it in an automated way, so that every day I will have the new prices and I can compare with the day before.
Automating
Running this whole process for an entire supermarket on my M1 MBP would take anywhere from 50m to 2h 30m, depending on the supermarket. I could also run all 3 scrapers in parallel with no noticeable difference.
However using my laptop was good for development and testing, but I needed a more permanent solution.
Use an old laptop?
The first attempt to a solution came in the form of an old laptop, dating all the way back to 2013.
It had dual core M-family processor clocked @ 2.20GHz and 4GB of RAM, which are on the low side especially by today's standards, but then again I only needed to open a single tab in a headless browser and navigate to a bunch of different URLs. Surely a dual core CPU with 4GB of RAM could handle that, right?
Well, not quite.
Even after bumping its memory to 12GB, the performance was far too disappointing, measuring in more than 2h even for the "fast" supermarket.1
Use the cloud?
So the next option was to use the cloud ☁️
My first thought was to use AWS, since that's what I'm most familiar with, but looking at the prices for a moderately-powerful EC2 instance (i.e. 4 cores and 8GB of RAM) it was going to cost much more than I was comfortable to spend for a side project.
At the time of writing, a c5a.xlarge instance is at $0.1640 per hour in
eu-north-1. That comes to a nice $118.08 per month, or $1,416.96 per year. Not so cheap.
So I turned to Hetzner.
The equivalent server there is cpx31, which is at $17.22 (€15.72) per month, or $206.64
per year, which is ~7 times cheaper than AWS, which makes it a no-brainer for my use case.
So Hetzner it is.
Use an old laptop AND the cloud!
Having settled on the cloud provider to run the scraping from, next step was to finally automate it and run it once per day.
The old laptop may not be powerful enough to run the scraping itself, but it was more than capable of running a CI server that just delegates scraping to the much beefier server from Hetzner.
My CI of choice is Concourse which describes itself as "a continuous thing-doer". While it has a bit of a learning curve, I appreciate its declarative model for the pipelines and how it versions every single input to ensure reproducible builds as much as it can.
Here's what the scraping pipeline looks like:
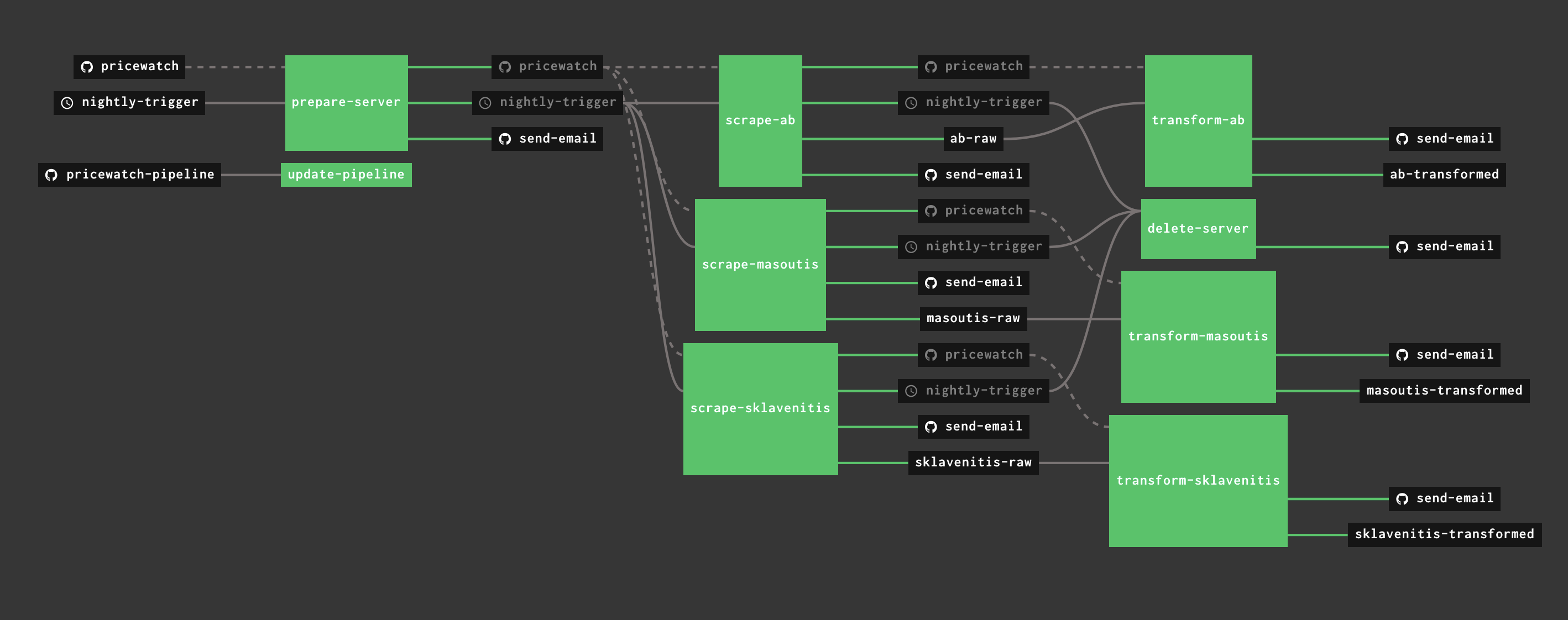 The scraping pipeline in concourse
The scraping pipeline in concourse
It has a nightly trigger which creates the scraping server and then triggers the three scraping jobs in parallel. When all of them are finished, it tears down the server to keep the costs down, and the raw output of each scraper is passed onto a job that transforms it to a format which is then loaded into pricewatcher.gr. Last, but definitely not least, when any of these steps fails I get an email alert.
Avoiding IP restrictions
But of course nothing is ever that simple.
While the supermarket that I was using to test things every step of the way worked fine, one of them didn't. The reason? It was behind Akamai and they had enabled a firewall rule which was blocking requests originating from non-residential IP addresses.
I had to find a way to do a "reverse vpn"2 kind of thing, so that the requests would appear to originate from my home IP.
Enter tailscale.
Tailscale allows you to put your devices on the same network even if, in reality, they are all over the place.
Once they are in the same network, then you can designate one of them to act as an "exit node". You can then tell the other devices to use the designated exit node and, from that point on, all their requests flow through there.
And if you're lucky like me, your ISP is using CGNAT, which basically means that your public IP address is not tied to you specifically, but it is shared with other customers of the ISP. This allows some flexibility and peace of mind that your IP won't be blindly blocked because that wouldn't affect just you.
So after all that, my good ol' laptop just got one more duty for itself:
Acting as an exit node for the scraping traffic.
How and when does it fail?
I've been running this setup for a year and a half now, and it has proved to be quite reliable.
Of course, as with any scraping project, you're always at the mercy of the developers of the website you're scraping, and pricewatcher is no exception.
There are 2 kinds of failures that I've faced: breaking changes and non-breaking changes.
The first one is easy: They changed something and your scraper failed. It may be something simple as running a survey so you have to click one more button, or something more complex where they completely change the layout and you have to make a larger refactor of your scraper.
The second kind is nastier.
They change things in a way that doesn't make your scraper fail. Instead the scraping
continues as before, visiting all the links and scraping all the products. However the way
they write the prices has changed and now a bag of chips doesn't cost €1.99 but €199,
because they now use <sup> to separate the decimal part:


To catch these changes I rely on my transformation step being as strict as possible with its inputs.
In both cases however, the crucial part is to get feedback as soon as possible. Because this runs daily, it gives me some flexibility to look at it when I have time. It can also be a source of anxiety in case something breaks when I'm off for 2 weeks for holidays. (Luckily they don't change their sites that often and that dramatically)
Optimising
While the overall architecture has remained pretty much the same since day 1, I've made several changes to almost all other aspects of how scraping works, to improve its reliability and to reduce the amount of work I had to do.
I configured email alerts for when things fail, heuristics that alert me when a scraping yields too many or too few products for that supermarket, timeouts, retries that don't start from the beginning, etc.
All of these could be a post of their own, and maybe they will (write a comment if you want!), but I want to highlight two other optimisations here.
The main bottleneck in this entire process is the duration of the scraping. The longer it takes, the more I end up paying and the more annoying it is if something fails and it needs to be retried from the beginning.
After lots of trial and error, two changes improved the times significantly: A bigger server and reducing the amount of data that I fetch.
Use a bigger server
I went from 4vCPUs and 16GB of RAM to 8vCPUs and 16GB of RAM, which reduced the duration by about ~20%, making it comparable to the performance I get on my MBP. Also, because I'm only using the scraping server for ~2h the difference in price is negligible.
Fetch fewer things
Part of the truncated snippet above is this bit, taken straight from the playwright docs:
def visit_links(self):
images_regexp = re.compile(r"(\.png?.*$)|(\.jpg.*$)")
for index, link in enumerate(self.links):
self.page.goto(link)
self.page.route(images_regexp, lambda route: route.abort())
#
# <truncated>
#
This aborts all requests to fetch images when I'm loading products. This not only makes the scraping quicker, but also saves bandwidth and, presumably, a few cents, for the websites.
While both of these are obvious in hindsight, sometimes it takes conscious effort to take a step back and re-examine the problem at hand. It also helps to talk about it out loud, either to a friend who knows or, even better, to a friend who doesn't know, for some rubber-duck debugging.
Cost
So how much does the scraping cost?
Accoring to the last invoice from Hetzner: €4.94 for the 31 servers I spinned up and €0.09 for the 31 IPv4 addresses they received.
The data from the scraping are saved in Cloudflare's R2 where they have a pretty generous 10GB free tier which I have not hit yet, so that's another €0.00 there.
Conclusion
These are the main building blocks of how I built a scraping pipeline for pricewatcher in order to keep track of how supermarkets change their prices.
Leave a comment below if it piqued your interest and/or you'd like me to dive a bit deeper in any area.
There's definitely something to be said here about websites being ridiculously heavy these days, but that's for another post.
VPNs hide your real IP address by proxying your connection through their own
servers. I wanted to do the opposite of that, and use my real IP address